
.png)
This article is a part 2 of a two part series about design tokens.
This is the link to the first part
In the first part of the series we’ve established why tokens are abuzz lately, what makes them useful and worth the hassle (common language instead of idiosyncrasies and dealing with modes effectively) and what the timeline of total tokenization might look like, which makes up for persuasive reasons why one should master dealing with tokens as soon as possible.
This part dives into a more opinionated prescription to how to think and model the work on tokens in a design system.
There are many articles that showcase slightly different takes on how tokens could be organized to be effective, but some common practices quickly start to emerge. This is my take after comparing and contrasting the different taxonomies people propose. To make it as clear and easy to understand as possible, we need to make sure 3 properties of tokens are taken into account:
1st property - alias vs core tokens
2nd property - simple vs composite tokens
3rd property - nested grouping of tokens
Alias vs core tokens
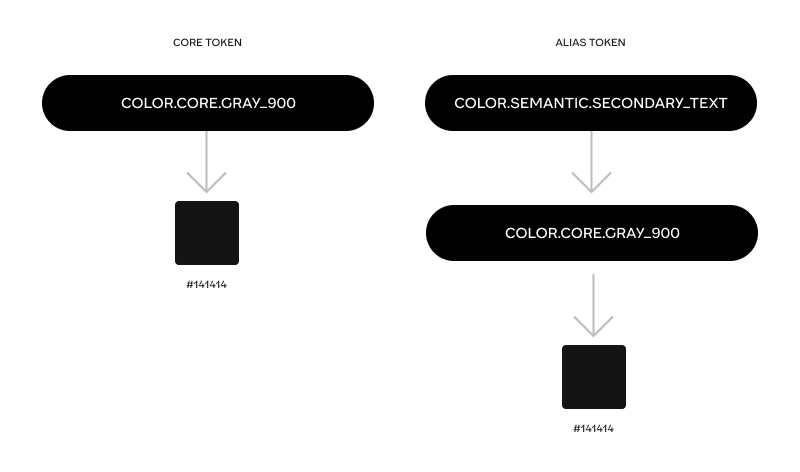
There’s a very important axis to distinguish between tokens: ‘what they are pointing to’. If they point to a concrete value (HEX color, 48px, Font family etc) they are ‘core’ tokens (sometimes called global, general, primitive). These tokens are basically like a palette of all the possible permutations of color, dimension, font family, shadow, border etc.. that our product can use, whether in one mode or another.
Core tokens are usually not directly connected to any specific mode. They are the base upon which the token tower builds.
Alias tokens can be of 2 kinds, ‘semantic’ or ‘specific’ (sometimes called component tokens, or scoped tokens), but in either case they always point to some other token, usually ‘core’, sometimes other semantic tokens, never to a concrete value. More on the difference between semantic and specific tokens later >>
Simple vs composite tokens
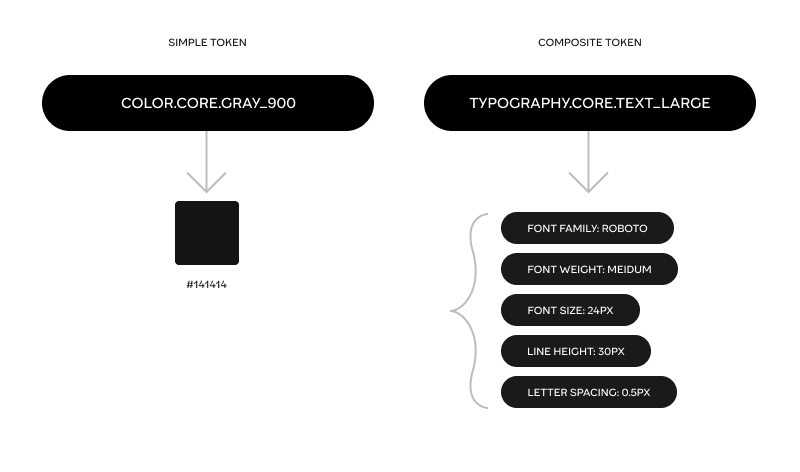
Another axis by which tokens can be divided is whether they are simple or composite. Simple tokens are of a type that can be expressed as one singular value, like: color, font family, font weight, dimension (whichever unit of measure), duration of an animation and an animation curve (cubic Bezier for example). There are probably more to come later on, but these are the ones so far.
Composite tokens are of a type that have to be represented as a set of values, with a rigid formation. For example shadow has to have both a color value, an x, y, spread and blur values. Border, typography, transition and gradient are all composite tokens as well.
Nested grouping of tokens
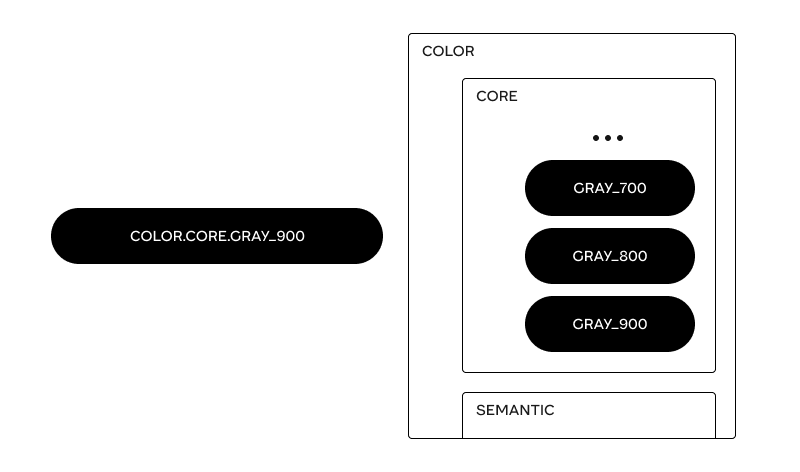
One ability that the token, formatted as JSON allows for - is grouping. This is important because grouping, and specifically nested grouping, is crucial to make a coherent and clear system to search, read and understand the meaning of tokens. Grouping is also the reason why tokens are written with dots separating words. A token's name is basically its ‘address’ in the foldering tree.
So ‘color.core.background.primary’ is basically the same as saying there’s a token named ‘primary’, and it resides inside ‘background’ which resides inside ‘core’ and the type of that token is color.
One important thing to remember is that composite tokens are not groups! Typography token type includes font family, font weight, size, line height and letter spacing, but it’s not that you can group these attributes together under a typography group. A valid group would be something like ‘headings’ and this group will include all the relevant composite typography tokens, each of which has their 5 values.
The recipe
Baring the three properties of tokens in mind - here’s the recipe, with ordered steps, I think makes the most sense:

Let’s go over those one by one, with detail:
First - Divide your tokens into their types. A full list of supported types can be found in the W3C community draft , as stated above some types will be simple, some composite.
Second - decide which modes or sets you are going to have. If it’s only a color theme like dark and light or maybe a density option, increased or reduced motion, color blindness mode, high contrast mode etc..
Third - start with one mode (for example light mode). In each of the token types create three prime folders, these folders are the only ones that are going to be persistent throughout all of the types. The prime folders are: ‘Core’, ‘Semantic’ and ‘Specific’. This is the place to establish the difference between the last two.
‘Semantic’ tokens are broad in terms of their reach but particular in terms of the meaning for the user. A great example is the semantic meaning of ‘success’ color (usually pointing to some core token like ‘green_500’ that points to a green-ish HEX value). Lots of things can be usefully tied to success - a border color, a text color, an icon color, a background of a chip or toast component. It has semantic weight for the user, she sees this color and can easily decipher its meaning in the UI. It very much might be that in dark mode the ‘success’ color token points to a different core token, perhaps ‘green_300’ but thanks to the aliasing all the borders, texts, icons and backgrounds that were tied to it - will change their rendition accordingly.
‘Specific’ tokens on the other hand have a very narrow reach, they are somewhere between ‘single-component-related’ to a ‘set-of-components-related’ that all share some common property to be targeted. For example - ‘modal_padding_horizontal’ is a specific token made to target all the different permutations of modal components (there could be many) and make sure they all share the same horizontal padding. It’s great for consistency, it’s great for particularity since we might not want to make our tooltips, toasts and popovers share the same padding values (so the specificity helps) but also it has no semantic meaning for the user, only for the designers, so it fits the ‘Specific’ folder well.
Fourth - keep ordering your tokens into subfolders inside the three prime folders until there’s nothing more to subdivide.
Fifth - create all the core tokens first by pointing them to values (color, dimension etc..)
Sixth - create all the semantic and specific tokens by pointing to the relevant core tokens in that one mode (light).
Seventh - duplicate the token set, rename it to the other mode (dark in our case) and change all the semantic and specific tokens so that they point to the correct core tokens for that mode.
Bonus - go ask your boss for a raise because you are doing dark magic and should be celebrated for that!
A few quirks of irregularity, because… life is chaotic
It’s easy to assume that all the token types are going to have relatively straight-forward t-shirt scales of core tokens - whether it’s a color palette of brand colors, neutral colors and viz colors, a palette of sizes, of spaces, of corner radii, of border width and style, of shadows (elevation) font families (hopefully not to many) and weights, but when it comes to semantic and specific - different types might look very different in terms of the usage of both of these.
For example it’s easy to come up with very meaningful semantic colors, because it’s well established that colors convey meaning in UI, but it’s a bit harder to come up with meaningful semantic tokens for dimensions because humans don’t ascribe much meaning to the sizes of paddings and widths of cards, tables and modals (it could be something like ‘selected’ semantic token for dimensions if the way a certain ui works is by making the selected object larger for example). On the other hand there’s going to be a swarm of specific dimension tokens as every component set would want to solidify its choices. In this case there would be a big number of specific tokens, a small number of semantic tokens (if any) all of which point to the palette of core tokens.
Borders might be the complete reversal of dimension with only semantic tokens and no specific ones (because borders are usually highly regular across the design system).
So don’t expect a very homogenous distribution of the three prime folders in each of the token types. Still - the mere existence of this ‘three-prime-folders-system’ helps make the whole token system be as regular, consistent and as readable as it can be.
Some design teams go into much detail about the rest of the subfolders with things like ‘attribute’ ‘purpose’ ‘prominence’ ‘state’ and ‘index’. But these are so irregularly dependent on each token type that I feel it’s best to leave it to the particularity of each specific design system, and their product’s unique quirks, but just to give a taste:
Attribute subfolder may divide into something like free / premium for, say, badges, cards buttons etc.
Purpose subfolder may divide into container / wrapper / surface / background etc.
Prominence subfolder may divide into primary / secondary / on_primary etc.
State subfolder may divide into on_hover / on_click / disabled / selected / error / success etc.
Index subfolder is usually added when there’s no more meaningful way to differentiate tokens and all you can do is to attribute t-shirt-like numbers to it, like animation.1 / animation.2 / animation.3 etc.
I hope this deep dive was helpful in illuminating the darker corners of design tokens, maybe even demystify them a little (I predict in a few years time it’s going to be as trivial as using styles in design tools is today). I hope that by now it’s clearer how we got here, why using tokens has merits, what’s special about now and how to actually go about creating a token system that works.
If you found this series interesting and helpful - I would see it as a token of appreciation (I couldn’t help it. Sorry. It’s stronger than me) if you share it with your colleagues!
Happy token building!
.png)
.png)
.png)